Learning Grasp Affordance Reasoning through Semantic Relations
This is a dataset that for visual grasp affordance prediction that promotes more robust and heterogeneous robotic grasping methods.
The dataset contains different attributes from 30 different objects. Each object instance is related not only to the semantic descriptions,
but also the physical features describing visual attributes, locations and different grasping regions related to a variety of actions.
We adopt the grasping ground truth labels from Robot Learning Lab (RLL) and use their
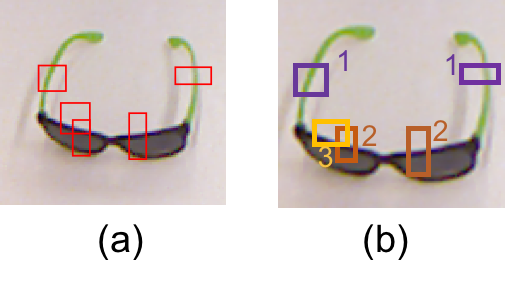
grasping regions [red rectangles in example Figure (a)] to label objects contained in the RLL and D-RGB Washington database . We use these adaptations as grasp affordance regions corresponding to different actions on an object.
For the features and labels of indoor locations we use AI2Thor and
MIT indoor scenes datasets and labels to train our model.
To know which of the stable grasping regions affords what action and under which context we conducted a survey using Figure-eight platform
to assign an affordance label to the regions [as numbers in the rectangles of Figure (b)].